从零开始部署ChatTTS,做一个属于自己的文字转语音
2024 年 6 月 3 日 星期一(已编辑)
/
1986
4
摘要
本文介绍了ChatTTS的安装和使用方法。首先,提供了官方模型的下载地址和设置代理的方式。接着,详细说明了正式安装和运行步骤。文章还提及如何自行编写API和使用推荐的图形界面,并提供了UI界面的截图。最后,文章总结了ChatTTS的各种调节功能,包括语速、角色保存、特殊符号和间隔等,认为这个开源项目虽刚推出,但听起来效果很好,具有很大的发展潜力,使用起来也相当方便。文章还附上了相关来源链接。
这篇文章上次修改于 2024 年 6 月 4 日 星期二,可能部分内容已经不适用,如有疑问可询问作者。
基础环境
# 我的环境
PyTorch 2.1.0
Python 3.10(ubuntu22.04)
Cuda 12.1有魔法可以跳过这一步
感谢 左涛 推动
如果没有魔法会报错的,下面给大家一个不用魔法的命令
官方模型地址是 : https://huggingface.co/2Noise/ChatTTS
设置代理就可以自由下载了: https://hf-mirror.com/
# Linux
vim ~/.bashrc
export HF_ENDPOINT=https://hf-mirror.com
source ~/.bashrc
# Window 使用 PowerShell
$env:HF_ENDPOINT = "https://hf-mirror.com"
# window 更简单版 (感谢 xiaoyu 推动)
# 在"环境变量" 中的"系统变量" 部分,点击 "新建"。
# 在 "变量名" 中输入 HF_ENDPOINT,在 "变量值" 中输入 "https://hf-mirror.com"正式安装
git clone https://github.com/2noise/ChatTTS.git
cd ChatTTS
pip install -r requirements.txt
# 感谢 MR.XING
conda install -c conda-forge pynini=2.1.5 && pip install WeTextProcessing
conda install -c conda-forge pynini=2.1.5 && pip install nemo_text_processing
#如果要启动webui.py 就多安装一下gradio
pip install gradio运行
python webui.py
#运行后他会自己下载模型到huggingface文件夹,需要自备魔法,或者用huggingface代理网站
#指定端口运行
python webui.py --server_port 1234自己编写api
#简单版 api.py 运行 python api.py
import ChatTTS
import torch
import torchaudio
from IPython.display import Audio
# 初始化 ChatTTS 模型
chat = ChatTTS.Chat()
chat.load_models(compile=False) # 如果需要更高性能,可以设置为 True
rand_spk = chat.sample_random_speaker()
# 要转换的文本
texts = ["你好,我是文字转语音"]
# 执行推理
wavs = chat.infer(texts)
# 保存音频文件
torchaudio.save("output1.wav", torch.from_numpy(wavs[0]), 24000)###################################
# 高级版 v-api.py 运行 python v-api.py
import ChatTTS
import torch
import torchaudio
from IPython.display import Audio
chat = ChatTTS.Chat()
chat.load_models(compile=False) # 如果需要更高性能,可以设置为 True
###################################
# Sample a speaker from Gaussian.
rand_spk = chat.sample_random_speaker()
params_infer_code = {
'spk_emb': rand_spk, # add sampled speaker
'temperature': .3, # using custom temperature
'top_P': 0.7, # top P decode
'top_K': 20, # top K decode
}
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = {
'prompt': '[oral_2][laugh_0][break_6]'
}
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wav = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
torchaudio.save("output2.wav", torch.from_numpy(wav[0]), 24000)好用的图形界面
感谢 Frazier Shaw 推荐
git clone https://github.com/jianchang512/ChatTTS-ui.git chat-tts-ui
cd chat-tts-ui
pip install -r requirements.txt
#默认端口是9966 修改的话
vim .env
python app.py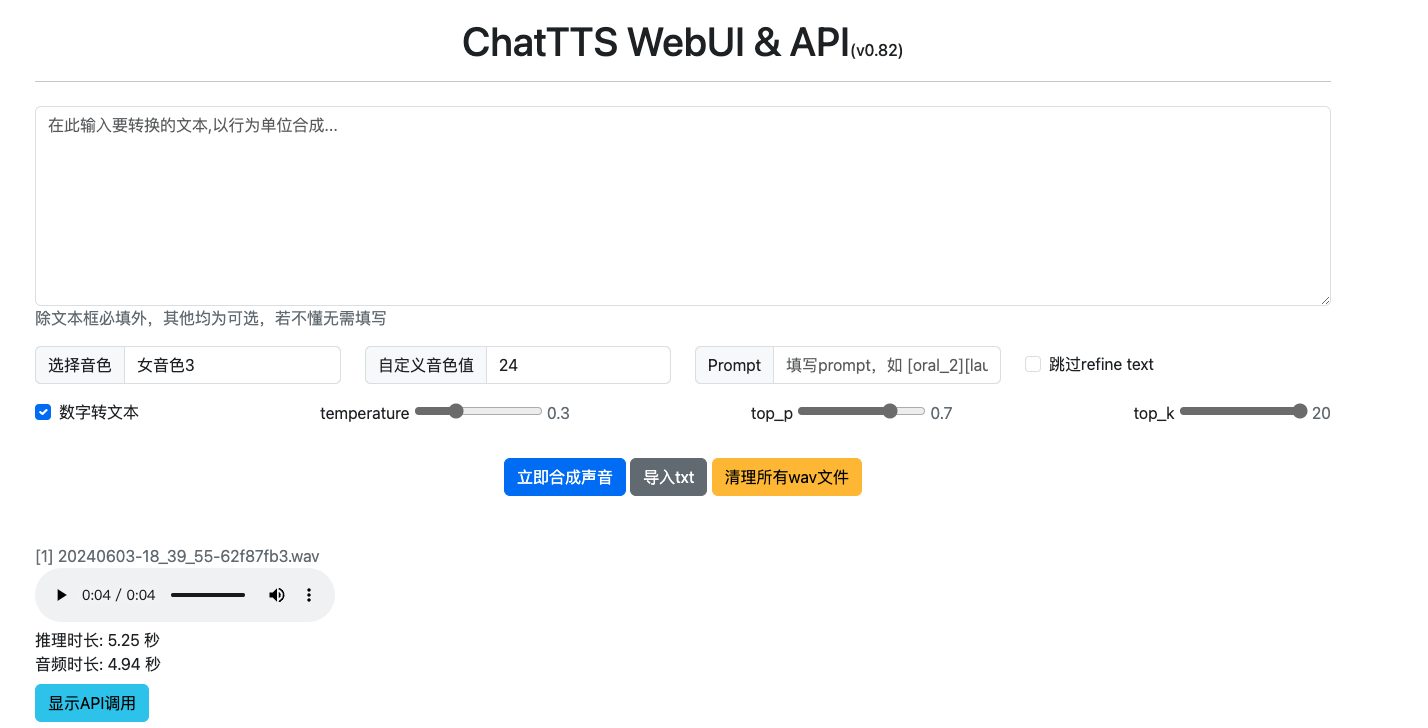
ChatTTS-ui
总结
里面还有很多调节,语速,随机角色保存,特殊符号 笑声,间隔等等,这个开源刚出来 ,但是听着很好听,成长空间很大。
自己可以做api来使用,挺方便
来源: